
cpu和gpu跑卷积神经网络关于gpu的函数卷积算法
深度学习
2024-06-24 11:00
996
联系人:
联系方式:
GPU加速下的函数卷积算法:性能提升与优化策略
一、引言
随着深度学习、计算机视觉等领域的快速发展,对高性能计算的需求日益增长。其中,函数卷积作为一种重要的数学运算,广泛应用于信号处理、图像处理等领域。然而,传统的CPU实现方式在处理大规模数据时存在效率低下的问题。因此,利用GPU强大的并行计算能力来加速函数卷积算法成为了一个重要的研究方向。本文将探讨如何在GPU上实现高效的函数卷积算法,并提出相应的优化策略。
二、GPU加速原理
GPU(图形处理器)最初是为图形渲染而设计的,但其强大的并行计算能力使其在科学计算领域得到了广泛应用。相比于CPU,GPU具有更多的核心和更高的内存带宽,能够同时处理大量的计算任务。这使得GPU在处理大规模数据时具有明显的优势。
三、函数卷积算法概述
函数卷积是一种数学运算,它将两个函数的值按照一定的权重进行叠加,得到一个新的函数。在信号处理中,卷积可以用来滤波、平滑等操作;在图像处理中,卷积可以用来提取特征、边缘检测等。函数卷积的计算量通常较大,尤其是在处理大规模数据时,因此需要高效的实现方式。
四、GPU上的函数卷积算法实现
- 数据传输与预处理
需要将待处理的函数数据从CPU传输到GPU内存中。为了提高数据传输效率,可以采用DMA(直接内存访问)技术,减少CPU的干预。可以对数据进行预处理,如归一化、量化等操作,以减少计算量和提高精度。
- 并行计算策略
在GPU上实现函数卷积算法时,需要充分利用其并行计算能力。可以将输入函数分割成多个子块,每个子块由一个线程块进行处理。在每个线程块内,又可以进一步划分成多个线程,每个线程负责计算一个或多个输出点的值。通过合理地分配计算任务,可以实现高效的并行计算。
- 内存管理
由于GPU具有独立的内存空间,因此在实现函数卷积算法时需要考虑内存管理问题。可以通过共享内存、纹理内存等技术来减少全局内存访问次数,从而提高计算效率。还可以采用分页内存管理策略,将不常用的数据存储在慢速内存中,以节省高速内存资源。
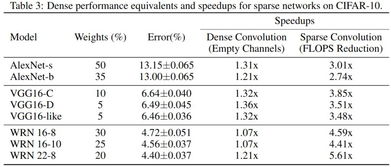
五、优化策略
- 循环展开与向量化
循环展开是一种常见的代码优化技术,它可以将嵌套循环中的内层循环展开为多个连续的语句,从而减少循环开销。在GPU上实现函数卷积算法时,可以利用循环展开技术来提高并行度。还可以结合向量化技术,将多个数据元素打包成一个向量进行处理,进一步提高计算效率。
- 缓存友好性优化
在GPU上实现函数卷积算法时,需要考虑数据的局部性和重用性。可以通过合理的内存布局和数据组织方式来提高缓存的命中率,从而减少全局内存访问次数。例如,可以将相邻的数据元素存储在同一行或同一列中,以便于缓存命中。
- 异构计算与多GPU协同工作
为了进一步提高计算效率,可以考虑采用异构计算技术,即同时使用CPU和GPU进行计算。对于不适合在GPU上执行的部分任务,可以将其放在CPU上完成。还可以通过多GPU协同工作来实现更高的计算性能。这需要在编程模型和通信机制上进行相应的支持。
六、总结与展望
本文介绍了在GPU上实现高效函数卷积算法的方法和优化策略。通过充分利用GPU的并行计算能力和内存带宽优势,并结合各种优化技术,可以实现比传统CPU实现方式更高效的函数卷积算法。展望未来,随着硬件技术的不断进步和编程模型的不断发展,相信会有更多创新性的方法和策略被提出和应用到这一领域中来。
GPU加速下的函数卷积算法:性能提升与优化策略
一、引言
随着深度学习、计算机视觉等领域的快速发展,对高性能计算的需求日益增长。其中,函数卷积作为一种重要的数学运算,广泛应用于信号处理、图像处理等领域。然而,传统的CPU实现方式在处理大规模数据时存在效率低下的问题。因此,利用GPU强大的并行计算能力来加速函数卷积算法成为了一个重要的研究方向。本文将探讨如何在GPU上实现高效的函数卷积算法,并提出相应的优化策略。
二、GPU加速原理
GPU(图形处理器)最初是为图形渲染而设计的,但其强大的并行计算能力使其在科学计算领域得到了广泛应用。相比于CPU,GPU具有更多的核心和更高的内存带宽,能够同时处理大量的计算任务。这使得GPU在处理大规模数据时具有明显的优势。
三、函数卷积算法概述
函数卷积是一种数学运算,它将两个函数的值按照一定的权重进行叠加,得到一个新的函数。在信号处理中,卷积可以用来滤波、平滑等操作;在图像处理中,卷积可以用来提取特征、边缘检测等。函数卷积的计算量通常较大,尤其是在处理大规模数据时,因此需要高效的实现方式。
四、GPU上的函数卷积算法实现
- 数据传输与预处理
需要将待处理的函数数据从CPU传输到GPU内存中。为了提高数据传输效率,可以采用DMA(直接内存访问)技术,减少CPU的干预。可以对数据进行预处理,如归一化、量化等操作,以减少计算量和提高精度。
- 并行计算策略
在GPU上实现函数卷积算法时,需要充分利用其并行计算能力。可以将输入函数分割成多个子块,每个子块由一个线程块进行处理。在每个线程块内,又可以进一步划分成多个线程,每个线程负责计算一个或多个输出点的值。通过合理地分配计算任务,可以实现高效的并行计算。
- 内存管理
由于GPU具有独立的内存空间,因此在实现函数卷积算法时需要考虑内存管理问题。可以通过共享内存、纹理内存等技术来减少全局内存访问次数,从而提高计算效率。还可以采用分页内存管理策略,将不常用的数据存储在慢速内存中,以节省高速内存资源。
五、优化策略
- 循环展开与向量化
循环展开是一种常见的代码优化技术,它可以将嵌套循环中的内层循环展开为多个连续的语句,从而减少循环开销。在GPU上实现函数卷积算法时,可以利用循环展开技术来提高并行度。还可以结合向量化技术,将多个数据元素打包成一个向量进行处理,进一步提高计算效率。
- 缓存友好性优化
在GPU上实现函数卷积算法时,需要考虑数据的局部性和重用性。可以通过合理的内存布局和数据组织方式来提高缓存的命中率,从而减少全局内存访问次数。例如,可以将相邻的数据元素存储在同一行或同一列中,以便于缓存命中。
- 异构计算与多GPU协同工作
为了进一步提高计算效率,可以考虑采用异构计算技术,即同时使用CPU和GPU进行计算。对于不适合在GPU上执行的部分任务,可以将其放在CPU上完成。还可以通过多GPU协同工作来实现更高的计算性能。这需要在编程模型和通信机制上进行相应的支持。
六、总结与展望
本文介绍了在GPU上实现高效函数卷积算法的方法和优化策略。通过充分利用GPU的并行计算能力和内存带宽优势,并结合各种优化技术,可以实现比传统CPU实现方式更高效的函数卷积算法。展望未来,随着硬件技术的不断进步和编程模型的不断发展,相信会有更多创新性的方法和策略被提出和应用到这一领域中来。

