
在Mac上轻松搭建PaddlePaddleGPU环境
人工智能
2024-03-27 00:34
860
联系人:
联系方式:
标题:在Mac上轻松搭建PaddlePaddle GPU环境
随着人工智能技术的飞速发展,深度学习框架如雨后春笋般涌现。在众多优秀的开源框架中,百度推出的PaddlePaddle以其独特的优势和强大的功能吸引了众多开发者的关注。然而,对于使用Mac系统的开发者来说,如何在本地搭建支持GPU加速的PaddlePaddle环境却是一个不小的挑战。本文将详细介绍如何在Mac系统上编译PaddlePaddle以支持GPU加速,让您的深度学习之旅更加顺畅。
一、准备工作
- 确保您的Mac系统已经安装了Xcode和Command Line Tools。您可以通过打开终端(Terminal)并输入以下命令来安装Command Line Tools:
xcode-select --install
- 安装Homebrew包管理器。如果您尚未安装Homebrew,请在终端中运行以下命令进行安装:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 通过Homebrew安装必要的依赖项。在终端中运行以下命令:
brew install cmake ninja
- 安装CUDA Toolkit。由于Apple Silicon M1芯片不支持NVIDIA GPU,因此只有基于Intel处理器的Mac才能使用CUDA。请访问NVIDIA官方网站下载适用于您的Mac版本的CUDA Toolkit。安装过程中,请确保选择“Add CUDA to the system PATH for all users”选项。
二、下载PaddlePaddle源码
- 访问PaddlePaddle GitHub仓库:https://github.com/PaddlePaddle/Paddle
- 点击页面右上角的“Clone or download”按钮,然后复制链接地址。
- 在终端中切换到您希望存放PaddlePaddle源码的目录,然后使用git命令克隆仓库:
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
三、编译PaddlePaddle
- 创建一个新的build目录,并在其中启动cmake配置过程:
mkdir build && cd build
cmake .. -G Ninja -DCUDA_ARCH_NAME="Maxwell" -DCMAKE_BUILD_TYPE=Release
请注意,这里我们指定了CUDA架构为“Maxwell”,这通常对应于NVIDIA的GTX 9xx系列显卡。如果您的显卡属于其他系列,请查阅相关文档以确定正确的架构名称。
2. 开始编译过程:
ninja
这个过程可能需要一段时间,具体取决于您的硬件性能。请耐心等待直至编译完成。
四、验证安装
- 编译完成后,您可以在终端中运行以下命令来验证PaddlePaddle是否成功安装并能够正确使用GPU资源:
python -c "import paddle; print(paddle.utils.gpu.device_count())"
如果输出结果为0,则表示未检测到可用的GPU设备;如果输出结果为正整数,则表示已成功检测到相应数量的GPU设备。
2. 为了进一步确认PaddlePaddle能够正常工作,您可以尝试运行一个简单的示例程序。例如,以下代码将创建一个线性回归模型并进行训练:
import paddle
from paddle.static import InputSpec
from paddle.static import nn
# 定义数据集
x = paddle.to_tensor([[1.0], [2.0], [3.0]])
y = paddle.to_tensor([[2.0], [4.0], [6.0]])
# 定义模型
class LinearRegression(nn.Layer):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 初始化模型
model = LinearRegression()
# 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 训练模型
for epoch in range(100):
y_pred = model(x)
loss = loss_fn(y_pred, y)
loss.backward()
optimizer.step()
optimizer.clear_grad()
print(f'Epoch {epoch 1}, Loss: {loss.numpy()[0]}')
运行上述代码后,您应该会看到损失值逐渐减小,这表明模型正在学习如何根据输入预测输出。
五、总结与展望
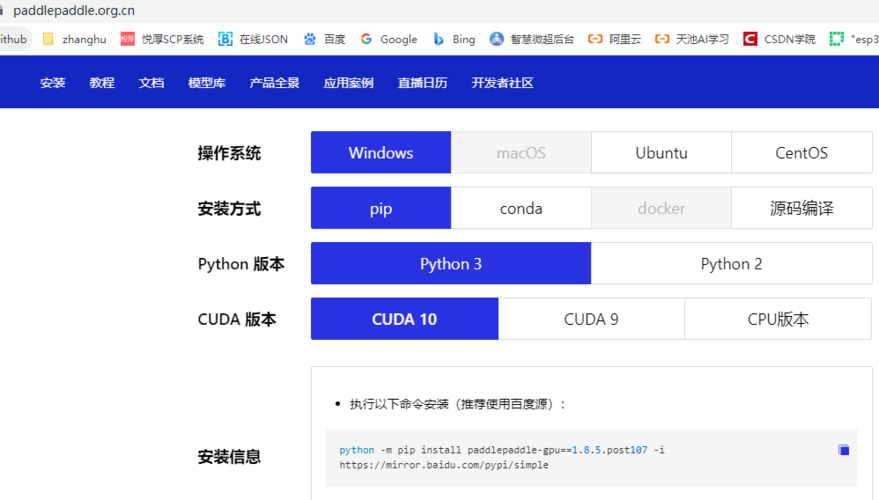
通过以上步骤,您应该能够在Mac系统上成功编译并安装支持GPU加速的PaddlePaddle环境。这将极大地提升您在深度学习领域的开发效率和实践能力。展望未来,随着软硬件技术的不断进步和创新,我们有理由相信深度学习领域将迎来更多激动人心的突破和发展机遇。让我们携手共进,共同探索这个充满无限可能的世界!
本站涵盖的内容、图片、视频等数据系网络收集,部分未能与原作者取得联系。若涉及版权问题,请联系我们进行删除!谢谢大家!
标题:在Mac上轻松搭建PaddlePaddle GPU环境
随着人工智能技术的飞速发展,深度学习框架如雨后春笋般涌现。在众多优秀的开源框架中,百度推出的PaddlePaddle以其独特的优势和强大的功能吸引了众多开发者的关注。然而,对于使用Mac系统的开发者来说,如何在本地搭建支持GPU加速的PaddlePaddle环境却是一个不小的挑战。本文将详细介绍如何在Mac系统上编译PaddlePaddle以支持GPU加速,让您的深度学习之旅更加顺畅。
一、准备工作
- 确保您的Mac系统已经安装了Xcode和Command Line Tools。您可以通过打开终端(Terminal)并输入以下命令来安装Command Line Tools:
xcode-select --install
- 安装Homebrew包管理器。如果您尚未安装Homebrew,请在终端中运行以下命令进行安装:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 通过Homebrew安装必要的依赖项。在终端中运行以下命令:
brew install cmake ninja
- 安装CUDA Toolkit。由于Apple Silicon M1芯片不支持NVIDIA GPU,因此只有基于Intel处理器的Mac才能使用CUDA。请访问NVIDIA官方网站下载适用于您的Mac版本的CUDA Toolkit。安装过程中,请确保选择“Add CUDA to the system PATH for all users”选项。
二、下载PaddlePaddle源码
- 访问PaddlePaddle GitHub仓库:https://github.com/PaddlePaddle/Paddle
- 点击页面右上角的“Clone or download”按钮,然后复制链接地址。
- 在终端中切换到您希望存放PaddlePaddle源码的目录,然后使用git命令克隆仓库:
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
三、编译PaddlePaddle
- 创建一个新的build目录,并在其中启动cmake配置过程:
mkdir build && cd build
cmake .. -G Ninja -DCUDA_ARCH_NAME="Maxwell" -DCMAKE_BUILD_TYPE=Release
请注意,这里我们指定了CUDA架构为“Maxwell”,这通常对应于NVIDIA的GTX 9xx系列显卡。如果您的显卡属于其他系列,请查阅相关文档以确定正确的架构名称。
2. 开始编译过程:
ninja
这个过程可能需要一段时间,具体取决于您的硬件性能。请耐心等待直至编译完成。
四、验证安装
- 编译完成后,您可以在终端中运行以下命令来验证PaddlePaddle是否成功安装并能够正确使用GPU资源:
python -c "import paddle; print(paddle.utils.gpu.device_count())"
如果输出结果为0,则表示未检测到可用的GPU设备;如果输出结果为正整数,则表示已成功检测到相应数量的GPU设备。
2. 为了进一步确认PaddlePaddle能够正常工作,您可以尝试运行一个简单的示例程序。例如,以下代码将创建一个线性回归模型并进行训练:
import paddle
from paddle.static import InputSpec
from paddle.static import nn
# 定义数据集
x = paddle.to_tensor([[1.0], [2.0], [3.0]])
y = paddle.to_tensor([[2.0], [4.0], [6.0]])
# 定义模型
class LinearRegression(nn.Layer):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 初始化模型
model = LinearRegression()
# 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 训练模型
for epoch in range(100):
y_pred = model(x)
loss = loss_fn(y_pred, y)
loss.backward()
optimizer.step()
optimizer.clear_grad()
print(f'Epoch {epoch 1}, Loss: {loss.numpy()[0]}')
运行上述代码后,您应该会看到损失值逐渐减小,这表明模型正在学习如何根据输入预测输出。
五、总结与展望
通过以上步骤,您应该能够在Mac系统上成功编译并安装支持GPU加速的PaddlePaddle环境。这将极大地提升您在深度学习领域的开发效率和实践能力。展望未来,随着软硬件技术的不断进步和创新,我们有理由相信深度学习领域将迎来更多激动人心的突破和发展机遇。让我们携手共进,共同探索这个充满无限可能的世界!
本站涵盖的内容、图片、视频等数据系网络收集,部分未能与原作者取得联系。若涉及版权问题,请联系我们进行删除!谢谢大家!
