
揭秘GPU指令读取机制如何高效处理并行计算
人工智能
2024-04-13 05:00
370
联系人:
联系方式:
随着计算机图形学和人工智能技术的飞速发展,图形处理器(GPU)已经成为了现代计算机系统中不可或缺的一部分。相较于传统的中央处理器(CPU),GPU在处理大规模并行计算任务时具有更高的效率和性能。那么,GPU是如何读取和处理指令的呢?本文将为您揭秘GPU指令读取机制。
一、GPU架构简介
在了解GPU如何读取指令之前,我们首先需要了解一下GPU的基本架构。GPU主要由以下几个部分组成:控制单元、算术逻辑单元、寄存器、缓存和内存接口等。其中,控制单元负责解析和执行指令;算术逻辑单元则负责进行各种数学运算;寄存器用于存储临时数据;缓存和内存接口则负责数据的读写操作。
二、指令读取过程
- 指令预取
当GPU开始执行一个程序时,它会从内存中预取一定数量的指令到指令缓存中。这一步骤的目的是为了减少因等待内存访问而导致的延迟。指令预取的数量通常取决于GPU的架构和当前的工作负载。
- 指令解码
预取到的指令会被送入控制单元进行解码。在这个过程中,控制单元会将指令分解为一系列的微操作(micro-operations),这些微操作可以被并行地执行。例如,一条加法指令可能会被分解为两个微操作:一个用于读取第一个操作数,另一个用于读取第二个操作数并进行加法运算。
- 微操作调度
解码后的微操作会被送入一个调度队列,由调度器根据当前的资源使用情况来决定它们的执行顺序。调度器的目的是最大化资源的利用率,以实现最高的性能。
- 微操作执行
一旦微操作被调度,它们就会被发送到相应的执行单元进行实际的计算。在执行过程中,结果会被写入到寄存器或者缓存中,以便后续的指令可以使用。
- 结果写回
计算得到的结果会被写回到内存或者显存中,供其他部分的程序使用。
三、总结
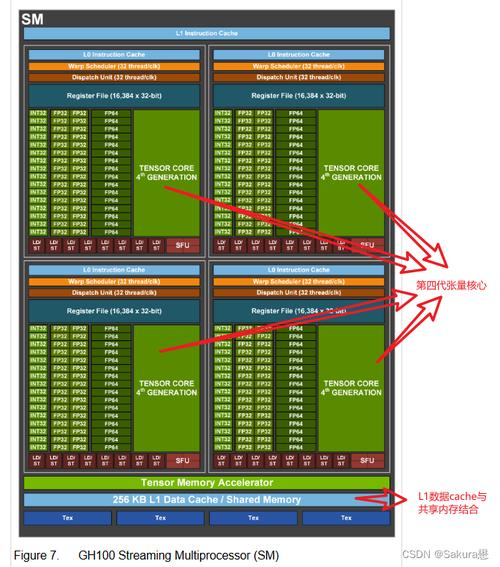
通过以上步骤,GPU可以高效地读取和处理指令,从而实现大规模的并行计算。这种高效的指令读取机制使得GPU在处理图形渲染、深度学习等任务时具有显著的优势。然而,这也对程序员提出了更高的要求,他们需要更加深入地理解GPU的架构和工作原理,才能编写出充分利用GPU性能的代码。
随着计算机图形学和人工智能技术的飞速发展,图形处理器(GPU)已经成为了现代计算机系统中不可或缺的一部分。相较于传统的中央处理器(CPU),GPU在处理大规模并行计算任务时具有更高的效率和性能。那么,GPU是如何读取和处理指令的呢?本文将为您揭秘GPU指令读取机制。
一、GPU架构简介
在了解GPU如何读取指令之前,我们首先需要了解一下GPU的基本架构。GPU主要由以下几个部分组成:控制单元、算术逻辑单元、寄存器、缓存和内存接口等。其中,控制单元负责解析和执行指令;算术逻辑单元则负责进行各种数学运算;寄存器用于存储临时数据;缓存和内存接口则负责数据的读写操作。
二、指令读取过程
- 指令预取
当GPU开始执行一个程序时,它会从内存中预取一定数量的指令到指令缓存中。这一步骤的目的是为了减少因等待内存访问而导致的延迟。指令预取的数量通常取决于GPU的架构和当前的工作负载。
- 指令解码
预取到的指令会被送入控制单元进行解码。在这个过程中,控制单元会将指令分解为一系列的微操作(micro-operations),这些微操作可以被并行地执行。例如,一条加法指令可能会被分解为两个微操作:一个用于读取第一个操作数,另一个用于读取第二个操作数并进行加法运算。
- 微操作调度
解码后的微操作会被送入一个调度队列,由调度器根据当前的资源使用情况来决定它们的执行顺序。调度器的目的是最大化资源的利用率,以实现最高的性能。
- 微操作执行
一旦微操作被调度,它们就会被发送到相应的执行单元进行实际的计算。在执行过程中,结果会被写入到寄存器或者缓存中,以便后续的指令可以使用。
- 结果写回
计算得到的结果会被写回到内存或者显存中,供其他部分的程序使用。
三、总结
通过以上步骤,GPU可以高效地读取和处理指令,从而实现大规模的并行计算。这种高效的指令读取机制使得GPU在处理图形渲染、深度学习等任务时具有显著的优势。然而,这也对程序员提出了更高的要求,他们需要更加深入地理解GPU的架构和工作原理,才能编写出充分利用GPU性能的代码。
